vLLm解决什么问题?
1. 显存碎片化与低效的 KV Cache 管理的问题
传统 LLM 推理框架(如 HuggingFace Transformers)需要为每个请求预分配 连续的显存空间 来存储 Key-Value(KV)缓存,导致显存浪费和无法共享KV Cache。
QKV是什么?
- Query (Q):表示当前 token 的“询问”向量,用于与所有 token 的 Key (K) 计算相似度(点积),从而得到注意力权重。
- Key(K):用于计算注意力权重(与 Query 的点积),决定其他 token 对当前 token 的重要性。
- Value(V):存储实际用于加权求和的信息,是注意力机制的“内容”。
怎么计算出QKV?
假设当前生成到第t=5个token:
-
K缓存:K=[K1,K2,K3,K4](形状 4×64)。
-
当前Query:Q5(形状 1×64)。
-
点积计算: \(Scores=\frac{Q_5 \cdot K^T}{\sqrt{64}} \in \mathbb{R}^{1 \times 4}\)
- 计算4个相似度值,对应与4个历史token的相关性。
-
Softmax后,得到权重向量 \(Weights \in \mathbb{R}^{1 \times 4}\)
-
输出:Weights V,其中 V 是历史Value的缓存(形状 4×64)。
为什么需要KV Cache?
自回归推理
\[P(x) = P(x_1) \cdot P(x_2|x_1) \cdot\cdot\cdot P(x_n|x_1,...,x_{n-1})\]在推理时,模型以自回归(autoregressive)方式生成文本,即每次根据已生成的token预测下一个token。每次生成新的token时,都需要计算当前token与所有历史token的注意力。
示例(生成序列 A→B→C→D):
- 生成
A:计算A的 K、V,存入缓存。 - 生成
B:计算B的 Q,与缓存的A的 K、V 计算注意力;生成B的 K、V 并加入缓存。 - 生成
C:计算C的 Q,与缓存的A、B的 K、V 计算注意力;更新缓存。 - 生成
D:同理复用缓存。
若不缓存历史信息,会导致以下问题:
- 重复计算:每次生成新 token 时,所有历史 token 的 Key(K)和 Value(V)都需要重新计算(例如生成
D时需重新计算A、B、C的 K、V)。 - 计算浪费:历史 token 的 K、V 在生成过程中是固定不变的,重复计算会带来大量冗余操作。
为什么不需要Q Cache ?
Query(Q)代表当前正在生成的 token 的“询问”向量,用于与历史 token 的 Key(K)计算注意力权重(即“哪些历史信息对我当前生成有用?”)。
Query 是当前 token 的瞬时属性,每次生成时必须重新计算,而历史 Q 无复用价值。相比之下,K 和 V 是历史 token 的静态表示,缓存它们可以避免大量冗余计算,直接提升推理效率。
现有的KV Cache有什么问题?
一起批处理的请求数量受到 GPU 内存容量的限制,尤其是分配给存储 KV 缓存的内存空间。随着请求数量的增加,KV 缓存的大小迅速增长。
以 13B 参数的 OPT 模型为例,单个token的 KV 缓存需要 800 KB 的空间,计算方式为 2(key和value向量)× 5120(hidden state size)× 40(number of layers)× 2(每个 FP16 的字节数)。由于 OPT 可以生成最多 2048 个token的序列,存储一个请求的 KV 缓存所需的内存可能高达 1.6 GB。并发 GPU 的内存容量在数十GB,即使将所有可用内存分配给 KV 缓存,也只能容纳数十个请求。
此外,根据当前趋势,GPU 的计算速度增长速度快于内存容量。例如,从 NVIDIA A100 到 H100,FLOPS 增加了 2 倍多,但 GPU 内存最大仍为 80GB,内存将成为越来越重要的瓶颈。
2. 低吞吐量 & 高延迟的问题
- 传统框架(如 HuggingFace)无法高效批处理请求,导致 GPU 计算资源利用率低,吞吐量受限7。
- 自回归生成(逐 Token 生成)导致 长序列推理延迟高,影响用户体验
3. 长序列推理的显存瓶颈问题
传统方法在处理超长上下文(如 128K Token)时,显存需求呈线性增长,导致 OOM(内存溢出)。
4. 高部署成本问题
LLM 推理需要大量 GPU 资源,传统方法显存占用高,导致 单卡可承载的并发请求数低,增加运营成本。
vLLm是如何解决的?
vLLM 采用集中式scheduler 来协调分布式 GPU worker,KV Cache Manager通过scheduler发送的指令以分页方式有效地管理Worker的 KV Cache。
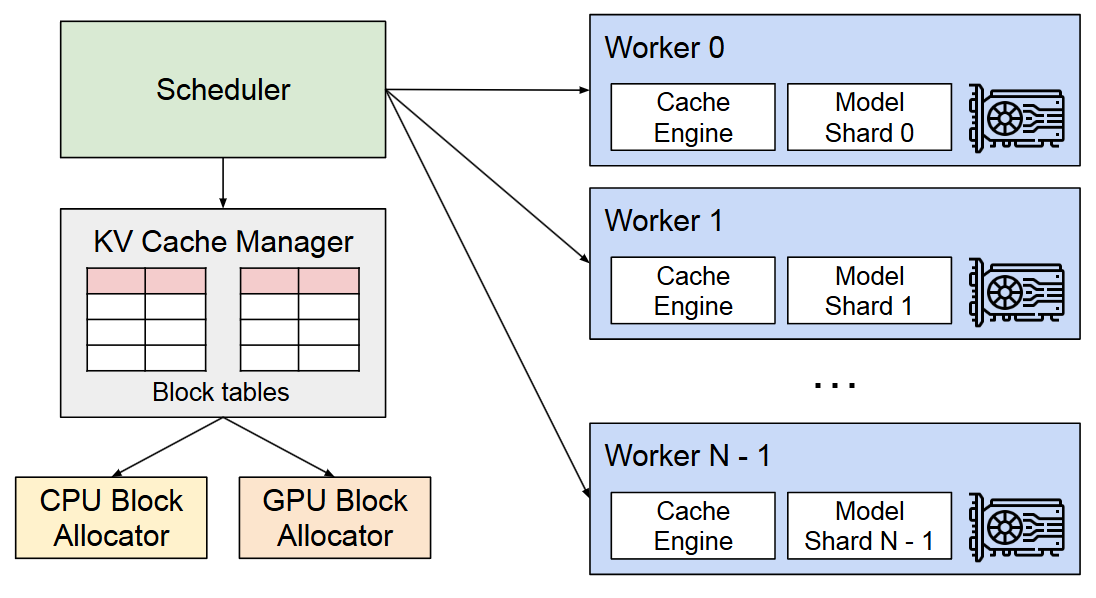
PagedAttention 允许将连续的Key和Value存储在非连续的内存空间中,即每个token的KV cache划分为KV blocks。每个block包含固定数量的token的KV向量。
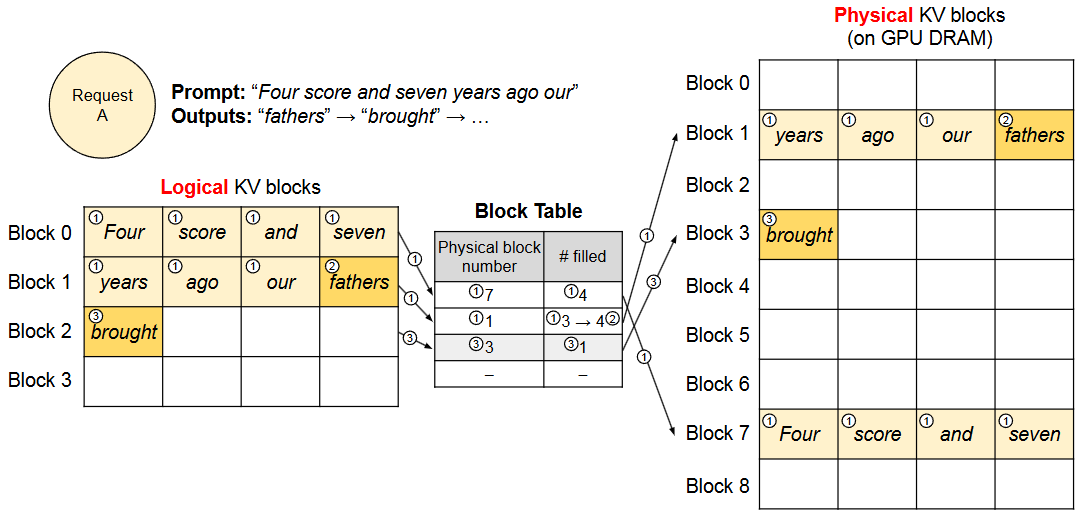
vLLM 最初不需要为可能生成的最大序列长度预留内存,它只预留必要的 KV blocks以容纳在prompt计算过程中生成的 KV cache。上图中prompt有 7 个token,所以vLLM将前两个逻辑 KV blocks(0 和 1)映射到两个物理 KV 块(分别为 7 和 1)。在预填充步骤中,vLLM使用传统的自注意力算法生成prompt的KV cache和第一个输出token。然后vLLM 将前 4 个token的 KV cache存储在逻辑块 0 中,并将随后的 3 个标记存储在逻辑块 1 中。并将随后的 3 个token存储在逻辑块 1 中,剩余的槽位保留用于后续的自回归生成阶段。
如何有效管理内存?
Decoding with PagedAttention
在全局范围内,对于每次Decoding迭代,vLLM 首先选择一组候选序列进行批处理,,并为新需要的逻辑块分配物理块。
随着更多token及其 KV cache生成,vLLM 会动态地为逻辑块分配新的物理块。由于所有块都是从左到右填充的,并且只有当所有之前的块都满了时才会分配新的物理块,所有内存浪费限制在一个块内,从而可以有效地利用所有内存。
Other Decoding Scenarios
Parallel Sampling
并行采样(Parallel Sampling,即同时生成多个候选输出)主要依赖其 动态批处理(Continuous Batching) 和 KV Cache 共享 机制。
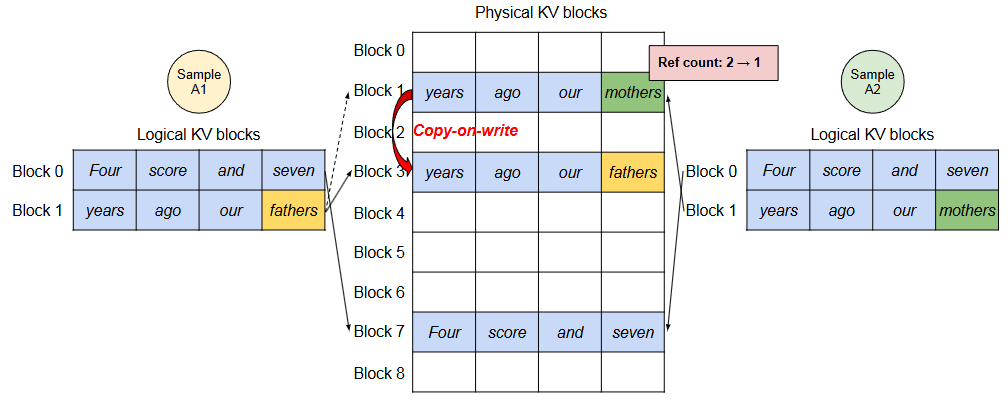
为每个物理块引入一个引用计数,vLLM 为需要由多个序列修改的物理块实现了块粒度的 copy-on-write机制,类似于操作系统虚拟内存中的写时复制技术。多个样本之间共享物理块,可以大大减少内存使用,特别是对于长输入prompts。
Beam Search束搜索
| Beam Search束搜索被广泛用于decode从LLM中输出的最可能的输出序列,因为它减轻了完全遍历的计算复杂度。该算法依赖于beam width参数𝑘,它决定了每一步保留的前 top 𝑘 个候选者的数量。在解码过程中,束搜索通过考虑所有可能的标记来扩展束中的每个候选序列,使用 LLM 计算它们的相应概率,并保留 𝑘 · | 𝑉 | 个候选者中概率最高的 top 𝑘 个序列,其中 | 𝑉 | 是词汇表大小。 |
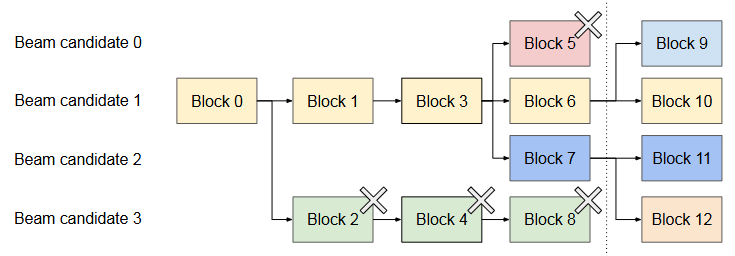
束搜索不仅共享初始prompt块,还共享不同candidates之间的其他块,并且随着decoding过程的推进,共享模式动态变化,类似于由复合分叉在操作系统创建的过程树。上图显示了 vLLM 如何管理束搜索示例中的 KV blocks,其中 k=4。在虚线所示的迭代之前,每个candidates序列都使用了 4 个完整的逻辑块。所有束candidates共享第一个块 0(即提示)。Candidate 3 从第二个块开始偏离其他候选者。Candidate 0-2 共享前三个块,并在第四个块处分叉。在随后的迭代中,前四个可能的candidate 都源自candidate 1 和 2。由于原始candidate 0 和 3 不再是top candidates,它们的逻辑块被释放,相应物理块的引用计数减少。vLLM 释放所有引用计数达到 0 的物理块(Block 2、4、5、8)。然后vLLM 为新candidate 分配新的物理块(block 9-12)以存储新的 KV cache。 现在,所有候选者共享块 0、1、3;candidate 0 和 1 共享block 6,而candidate 2 和 3 进一步共享block 7。
如何处理可变长度的输入和输出序列?
- 输入阶段:接收不同长度的请求,为每个序列创建逻辑块映射表,按需分配物理页存储初始KV Cache。
- 推理阶段:
- 使用PagedAttention机制,在计算注意力时动态索引各序列的物理页。
- 每生成一个token后,检查各序列状态,动态调整批次组成。
- 输出阶段:当序列达到终止条件(如生成结束符),立即释放其占用的物理页,资源实时回收。
调度和抢占
vLLM 采用先到先服务(FCFS)调度策略处理所有请求。需要回答两个经典问题:(1)应该驱逐哪些块?(2)如果需要再次使用,如何恢复被驱逐的块?
Swapping
除了 GPU 块分配器外,vLLM 还包括一个 CPU 块分配器来管理交换到 CPU RAM 的物理块。当 vLLM 耗尽为新token分配的空闲物理块时,它选择一组要替换的序列,并将它们的 KV 缓存转移到 CPU。一旦它抢占了一个序列并替换了其块,vLLM 将停止接受新请求,直到所有抢占的序列都完成。一旦请求完成,其块将从内存中释放,抢占的序列的块将被重新带入以继续处理该序列。请注意,在这种设计中,交换到 CPU RAM 的块的数量永远不会超过 GPU RAM 中总物理块的数量,因此 CPU RAM 上的交换空间由为 KV cache分配的 GPU 内存所限制。
Recomputation
当抢占的序列重新调度时,只需重新计算 KV cache。请注意,重新计算延迟可以显著低于原始延迟,因为decode时生成的token可以与原始用户prompt 连接起来作为新的prompt ——它们在所有位置的 KV cache可以在一个prompt 阶段迭代中生成。
Swapping和Recomputation的性能取决于 CPU、RAM 和 GPU 内存之间的带宽以及 GPU 的计算能力。
Kernel-level Optimization
(1)Fused reshape and block write。在每一个 Transformer 层中,新的 KV 缓存被分割成块,重塑为优化块读取的内存布局,然后根据块表保存到指定位置。为了最小化内核启动开销,我们将它们融合成一个内核。(2)Fusing block read and attention。我们将 FasterTransformer中的注意力内核调整为根据块表读取 KV cache,并实时执行注意力操作。为了确保内存访问的连续性,我们为每个块分配一个 GPU warp 进行读取。此外还增加了对请求批次内可变序列长度的支持。
(3)Fused block copy。由写时复制机制发出的块复制操作可能作用于不连续的块。如果我们使用 cudaMemcpyAsync API,这可能导致大量小数据移动的调用。为了减轻开销,我们实现了一个内核,将不同块的复制操作批处理成一个内核启动。
如何在分布式环境中工作?
主要通过 张量并行(Tensor Parallelism) 和 流水线并行(Pipeline Parallelism) 实现多 GPU 或多节点的推理加速
张量并行(Tensor Parallelism)
- 原理:将模型的权重矩阵(如注意力头的 Q/K/V 计算、FFN 层)拆分到多个 GPU 上,每个 GPU 计算部分结果,最后通过通信(如 AllReduce)合并输出。通过在 Transformers 上支持广泛使用的 Megatron-LM 风格张量模型并行策略,该策略遵循 SPMD(单程序多数据)执行调度,其中线性层被分割执行块矩阵乘法。具体来说,注意力算子是在注意力头维度上拆分的,每个 SPMD 进程负责多头注意力中的一部分注意力头。
- 配置参数:通过
--tensor-parallel-size指定 GPU 数量(如--tensor-parallel-size=4表示 4 块 GPU 并行)。 - 优势:适用于单服务器多 GPU 场景,减少单卡显存压力,提升计算效率。
流水线并行(Pipeline Parallelism)
- 原理:将模型按层拆分到不同节点(服务器),每个节点处理部分层计算,通过流水线方式传递中间结果。
- 配置参数:通过
--pipeline-parallel-size控制节点数(如--pipeline-parallel-size=2表示跨 2 个节点)。 - 适用场景:超大规模模型(如千亿参数)或单节点显存不足时使用,但通信开销较大,实测中单服务器多 GPU 场景下性能可能不如张量并行。
多节点部署
- Ray 框架集成:vLLM 使用 Ray 协调多节点间的任务调度和通信6。
- 主节点:启动 Ray 服务(
ray start --head)。 - 工作节点:加入集群(
ray start --address=<主节点地址>)。 - API 服务:在主节点启动服务时指定总 GPU 数量(如
--tensor-parallel-size=8跨 8 块 GPU)
- 主节点:启动 Ray 服务(