vLLM 生产栈 的可观测性
Kube-Prometheus-Stack 和 Prometheus Adapter 部署说明
kube-prometheus-stack:
- 包含 Prometheus、Grafana 和 Alertmanager
- 提供 Kubernetes 集群的全面监控
- 包含预定义的仪表盘和告警规则
prometheus-adapter:
- 将 Prometheus 指标转换为 Kubernetes 自定义指标
- 允许使用 Prometheus 指标进行 Horizontal Pod Autoscaling (HPA)
kube-prom-stack.yaml
## Create default rules for monitoring the cluster
#
# Disable `etcd` and `kubeScheduler` rules (managed by DOKS, so metrics are not accessible)
defaultRules:
create: true
rules:
etcd: false
kubeScheduler: false
## Component scraping kube scheduler
##
# Disabled because it's being managed by DOKS, so it's not accessible
kubeScheduler:
enabled: false
## Component scraping etcd
##
# Disabled because it's being managed by DOKS, so it's not accessible
kubeEtcd:
enabled: false
alertmanager:
## Deploy alertmanager
##
enabled: true
# config:
# global:
# resolve_timeout: 5m
# slack_api_url: "<YOUR_SLACK_APP_INCOMING_WEBHOOK_URL_HERE>"
# route:
# receiver: "slack-notifications"
# repeat_interval: 12h
# routes:
# - receiver: "slack-notifications"
# # matchers:
# # - alertname="EmojivotoInstanceDown"
# # continue: false
# receivers:
# - name: "slack-notifications"
# slack_configs:
# - channel: "#<YOUR_SLACK_CHANNEL_NAME_HERE>"
# send_resolved: true
# title: "\n"
# text: "\n"
# additionalPrometheusRulesMap:
# rule-name:
# groups:
# - name: emojivoto-instance-down
# rules:
# - alert: EmojivotoInstanceDown
# expr: sum(kube_pod_owner{namespace="emojivoto"}) by (namespace) < 4
# for: 1m
# labels:
# severity: 'critical'
# alert_type: 'infrastructure'
# annotations:
# description: ' The Number of pods from the namespace is lower than the expected 4. '
# summary: 'Pod in namespace down'
## Using default values from https://github.com/grafana/helm-charts/blob/main/charts/grafana/values.yaml
##
grafana:
enabled: true
adminPassword: prom-operator # Please change the default password in production !!!
# affinity:
# nodeAffinity:
# preferredDuringSchedulingIgnoredDuringExecution:
# - weight: 1
# preference:
# matchExpressions:
# - key: preferred
# operator: In
# values:
# - observability
# # Starter Kit setup for DigitalOcean Block Storage
# persistence:
# enabled: true
# storageClassName: do-block-storage
# accessModes: ["ReadWriteOnce"]
# size: 5Gi
## Manages Prometheus and Alertmanager components
##
prometheusOperator:
enabled: true
## Deploy a Prometheus instance
##
prometheus:
enabled: true
# Monitor vLLM pods using ServiceMonitor
additionalServiceMonitors:
- name: "vllm-monitor"
selector:
matchLabels:
app.kubernetes.io/managed-by: Helm
environment: test
release: test
namespaceSelector:
matchNames:
- default
endpoints:
- port: "service-port"
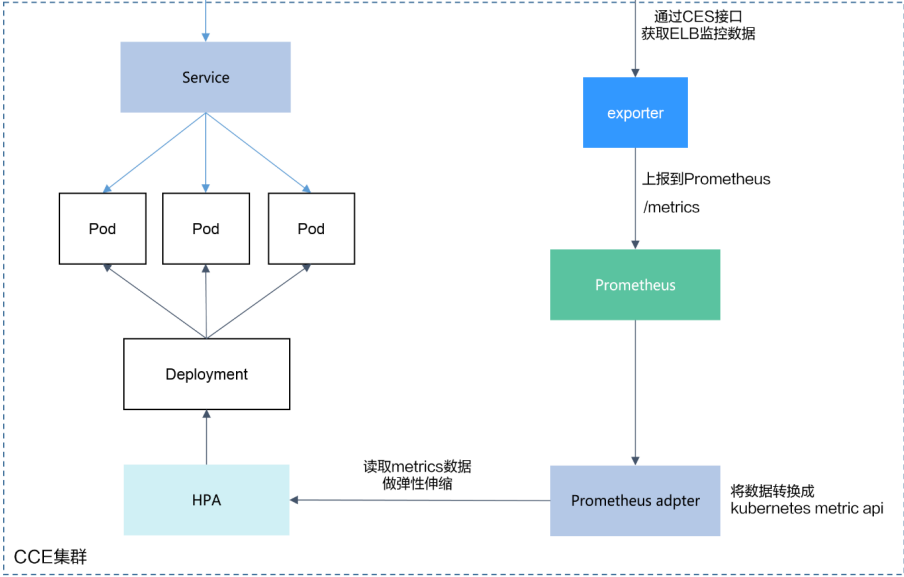
- 默认告警规则:
- 禁用了 etcd 和 kube-scheduler 的监控规则(因为这些组件由 DigitalOcean Kubernetes 管理)
- 组件监控:
- 禁用了 kube-scheduler 和 etcd 的监控(不可访问)
- Alertmanager:
- 已启用,但默认没有配置通知(注释部分展示了如何配置 Slack 通知)
- Grafana:
- 已启用,默认管理员密码为 “prom-operator”
- 注释部分展示了如何配置持久化存储
- Prometheus:
- 已启用
- 配置了额外的 ServiceMonitor 来监控 vLLM 服务
prom-adapter.yaml
loglevel: 1
prometheus:
url: http://kube-prom-stack-kube-prome-prometheus.monitoring.svc
port: 9090
rules:
default: true
custom:
# Example metric to export for HPA
- seriesQuery: '{__name__=~"^vllm:num_requests_waiting$"}'
resources:
overrides:
namespace:
resource: "namespace"
name:
matches: ""
as: "vllm_num_requests_waiting"
metricsQuery: sum by(namespace) (vllm:num_requests_waiting)
- Prometheus 连接配置:
- 指定了 Prometheus 服务的 URL 和端口
- 自定义规则:
- 定义了一个示例规则来暴露 vLLM 的请求等待数指标
- 将
vllm:num_requests_waiting指标转换为vllm_num_requests_waiting自定义指标
整体类似如下
Quick Start
uv venv myenv --python 3.12 --seed
source myenv/bin/activate
uv pip install vllm
在虚拟环境中安装 Jupyter 内核支持
pip install ipykernel
将虚拟环境添加到 Jupyter
python -m ipykernel install --user --name=你的环境名
验证内核是否添加成功
jupyter kernelspec list
使用modelscope,并设置缓存路径
export VLLM_USE_MODELSCOPE=true
export MODELSCOPE_CACHE=/root/autodl-tmp/modelscope
运行以下命令以启动使用 Qwen2.5-1.5B-Instruct 模型的 vLLM 服务器:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
export CUDA_EMPTY_CACHE=1
列出指定目录下最大的文件
du -h --max-depth=1 /root | sort -hr