huggingface开放 LLM 排行榜
Qwen/QwQ-32B-Preview
DeepSeek-R1-Distill-Qwen-32B
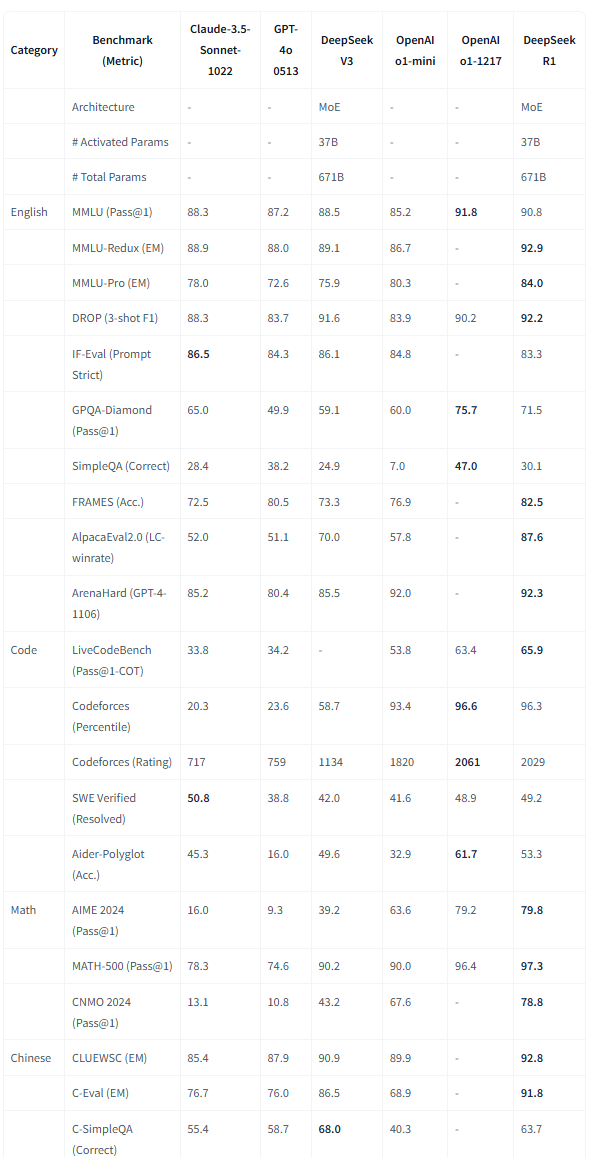
DeepSeek-R1
Benchmark
- MMLU(Massive Multitask Language Understanding)(https://huggingface.co/datasets/cais/mmlu)包含57个子任务,涵盖STEM(科学、技术、工程、数学)、人文、社科等广泛领域,例如初等数学、美国历史、计算机科学、法律等。
- BBH(BigBench Hard)BigBench 数据集中筛选出的 23 个高难度任务,要求模型具备复杂推理能力,如逻辑分析、多步问题解决等。https://github.com/google/BIG-bench/tree/main
- IF-EVAL(Instruction Following Evaluation)测试模型遵循明确指令的能力,例如“必须包含关键词 X”或“使用格式 Y”。通过量化模型对指令的遵守程度(如关键词覆盖率、格式正确率)评估其可控性。
- MMLU-PRO是MMLU 的增强版本,包含 12,000 个跨学科复杂问题,通过增加选项数量(从 4 到 10)、专家审核、思维链(CoT)推理导向,显著提升评测难度。
- GPQA(Graduate-Level Google-Proof Q&A)由领域专家设计的困难知识问答基准,涵盖生物学、物理、化学等学科的博士级问题,外行人难以回答,但专家可轻松解决。
- MATH面向数学推理的评测数据集,收录高中竞赛级数学题,使用LaTeX 格式表示方程,Asymptote 绘制图形,强调数学符号处理与逻辑推理能力。
- C-Eval:适用于大语言模型的多层次多学科中文评估套件。https://huggingface.co/datasets/ceval/ceval-exam
任务性能评估
1.1 自然语言理解
- 指标:准确率(Accuracy)、F1分数(精准率和召回率的调和平均值)、精确率(Precision)、召回率(Recall)等。
1.2 自然语言生成
- 指标:
- BLEU(机器翻译):基于n-gram重叠率。
- ROUGE(文本摘要):衡量召回率。
- METEOR:结合同义词和词形变化的改进版BLEU。
- Perplexity(困惑度):衡量模型对测试数据的预测能力。
技术方法与工具
- 自动化评估工具
- 开源工具链:HuggingFace的Evaluate库支持200+指标计算,DeepEval提供可定制评测流水线
- 混合评估范式
- 白盒+黑盒协同:先用DIKWP定位模型认知短板(如意图理解不足),再通过MT-Bench验证整体性能提升
- 人机协同评估:对关键任务(如法律文书生成)采用专家评审(30%)+AI自动评分(70%)的混合机制
Finance 领域
数据集:
FinEval是一个中文金融领域高质量多项选择与文本问答题的集合。https://github.com/SUFE-AIFLM-Lab/FinEval
Benchmarking :
FinanceBench:金融问答新基准https://github.com/patronus-ai/financebench
AlphaFin: 基于检索增强股票链框架的金融分析基准测试 (https://github.com/AlphaFin-proj/AlphaFin/tree/main)
大模型:
BloombergGPT: A Large Language Model for Finance(https://arxiv.org/abs/2303.17564)
Survey:
A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges(https://arxiv.org/abs/2406.11903)