什么是微调Fine-tuning?
微调是指在预训练模型的基础上,使用特定任务(如文本分类、摘要生成)或领域(如法律、医学)的数据集对模型进行一步训练的过程。预训练模型通常在大规模、通用语料库上训练,学习了丰富的语言模型和知识。
微调的方法分类
(1) 全参数微调(Full Fine-tuning)
更新模型所有参数。
(2) 参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
- LoRA(Low-Rank Adaptation):为权重矩阵添加低秩分解的适配器。
- Adapter Layers:在模型层间插入小型可训练模块。
- Prompt Tuning:学习软提示(Soft Prompts)引导模型输出。
- Prefix Tuning:在输入前添加可训练的前缀向量。
(3) 指令微调(Instruction Tuning)
- 适用场景:增强模型遵循指令的能力(如 ChatGPT)。
- 数据形式:输入为指令(如“写一首诗”),输出为对应结果。
微调的应用场景
- 任务导向:文本分类、命名实体识别(NER)、机器翻译。
- 领域适应:医疗诊断、法律文书生成、金融报告分析。
- 对话系统:客服机器人、个性化聊天助手。
- Few-shot/Zero-shot 学习:通过微调少量样本提升小样本任务表现。
工具与框架
- Hugging Face Transformers:提供预训练模型和微调接口(如
Trainer类)。 - PyTorch/TensorFlow:灵活实现自定义训练流程。
- PEFT 库:支持 LoRA、Adapter 等高效微调方法。
- 分布式训练:使用 DeepSpeed、FairScale 加速大规模模型训练。
LoRA
LoRA假设模型在适配新任务时,权重变化(ΔW)具有低秩性(即可以用低维矩阵近似表示)。因此,它通过向原始权重中注入低秩分解矩阵来间接更新参数,大幅减少可训练参数量。
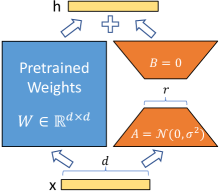
对于一个预训练的权重矩阵 W0∈ℝd×k ,我们通过将其后者表示为低秩分解 W0+ΔW=W0+BA 来约束其更新,其中 B∈ℝd×r,A∈ℝr×k ,秩 r≪min(d,k) 。在训练过程中, W0 被冻结,不接收梯度更新,而 A 和 B 包含可训练参数。注意 W0 和 ΔW=BA 与相同的输入相乘,它们的输出向量在坐标上相加。
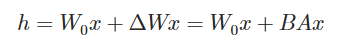
LoRA 在 PEFT 中的实现步骤
在 PEFT 库(如 Hugging Face 的 peft 库)中,LoRA 的实现主要通过配置参数并将其应用到预训练模型来完成。以下是具体的实现步骤:
配置 LoRA 参数
首先,需要通过 LoraConfig 类定义 LoRA 的配置参数。这些参数决定了 LoRA 的行为和应用范围:
- r:低秩矩阵的秩,通常是一个较小的整数(如 8 或 16),控制新增参数的数量。
- lora_alpha:缩放因子,用于调整 LoRA 的更新幅度,通常设置为 16 或 32。
- target_modules:指定将 LoRA 应用于模型的哪些模块,通常是注意力层(如 q_proj、v_proj)或全连接层。
- lora_dropout:dropout 概率,用于正则化,避免过拟合。
- task_type:任务类型,例如因果语言建模(TaskType.CAUSAL_LM)或序列分类。
Self-Instruct
Self-Instruct 是用于提升语言模型性能的方法,核心思想是让模型通过自我生成指令数据来微调自身,从而更好地理解和遵循人类指令。
1. 种子指令准备(Seed Instructions)
- 目标:提供少量高质量的初始指令示例,作为模型生成新指令的起点。
- 方法:
- 人工编写或从现有数据集中收集 50-200 条指令(如“写一首关于春天的诗”“解释什么是光合作用”)。
- 这些指令需覆盖多样化任务类型(生成、分类、问答、推理等)。
- 关键点:种子数据的质量直接影响后续生成数据的多样性,需避免任务类型或领域的单一性。
2. 生成新指令(Instruction Generation)
-
目标:基于种子指令,引导模型生成大量新指令。
-
方法:
- Prompt 设计:向模型输入种子指令示例,并附加生成指令的引导语句(例如:“请生成与以下任务类似但不同的新指令:”)。
- 多样性控制:通过温度参数(Temperature)调节生成结果的随机性,避免重复。
- 任务类型扩展:要求模型生成不同形式的指令,如:
- 开放式生成(如“写一个科幻故事”)
- 分类任务(如“判断这句话的情感是正面还是负面”)
- 问答任务(如“为什么天空是蓝色的?”)
-
示例:
输入(种子指令): “写一首关于秋天的诗” 模型生成: “写一个关于机器人的冷笑话”
3. 指令去重与过滤(Instruction Filtering)
- 目标:剔除低质量、重复或无效指令。
- 方法:
- 去重:通过字符串匹配或语义相似度模型(如Sentence-BERT)去除重复指令。
- 质量过滤:
- 规则过滤:剔除包含敏感词、语法错误或模糊描述的指令。
- 模型打分:用预训练模型(如GPT-3)对生成指令的可执行性和合理性打分,保留高分指令。
- 多样性筛选:确保指令覆盖不同领域(科学、艺术、日常等)和任务类型。
4. 生成输入-输出对(Input-Output Generation)
-
目标:为每个指令生成对应的输入(可选)和输出(答案)。
-
方法:
- 输入生成(若任务需要上下文):
- 例如,对指令“总结以下文章”,模型需先生成一篇示例文章作为输入。
- 输出生成:
- 使用模型生成符合指令的答案(如对“解释量子力学”,生成一段科普文本)。
- 通过控制生成参数(如
max_length、top_p)确保输出质量。
- 输入生成(若任务需要上下文):
-
示例:
指令: “将这句话翻译成法语: 'Hello, how are you?'” 输入: “Hello, how are you?” 输出: “Bonjour, comment ça va ?”
5. 数据验证与修正(Validation & Correction)
- 目标:确保生成的输入-输出对准确符合指令要求。
- 方法:
- 自动验证:
- 规则检查(如翻译任务需验证语言是否正确)。
- 使用另一个模型对输入-输出对进行打分(如通过GPT-4评估答案合理性)。
- 人工抽检(可选):对部分数据人工审核,修正错误样本。
- 自动验证:
6. 迭代微调(Iterative Fine-Tuning)
- 目标:用生成的数据逐步优化模型。
- 方法:
- 混合数据训练:将生成的指令数据与原始人工数据混合,进行监督微调(Supervised Fine-Tuning)。
- 多轮迭代:
- 每轮微调后,用更新后的模型生成更多指令,形成“生成→过滤→训练”的闭环。
- 逐步提升生成数据的复杂性和多样性。
- 关键点:需控制每轮生成数据的规模,避免模型陷入局部最优(过度拟合生成的数据模式)。
7. 评估与调整(Evaluation)
- 目标:验证模型在新任务上的泛化能力。
- 方法:
- 保留测试集:使用未参与训练的人工标注指令数据测试模型表现。
- 指标衡量:
- 任务成功率:模型正确响应指令的比例。
- 多样性评分:生成结果的丰富程度(如通过熵值计算)。
- 失败分析:针对错误案例调整生成或过滤策略(例如补充某类任务的种子数据)。