以太坊中MPT树的结构
每一个以太坊的区块头都包含三棵MPT树,分别是交易树、收据树(交易执行过程中的一些数据)和状态树(账号信息、合约账户和用户账户)。MPT(Merkle Patricia Trie)是以太坊中一种非常重要的数据结构,用来存储用户账户的状态及其变更、交易信息、交易的收据信息。它实际上是三种数据结构的组合,分别是Trie树, Patricia Trie和Merkle树。下面分别介绍这三种数据结构。
(1)Trie 树:
Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树。Trie树可以利用字符串的公共前缀来节约存储空间。如下图所示,该trie树用10个节点保存了6个字符串:tea,ten,to,in,inn,int:
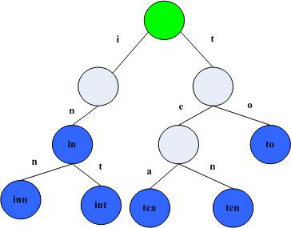
在该trie树中,字符串in,inn和int的公共前缀是“in”,因此可以只存储一份“in”以节省空间。当然,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存,这也是trie树的一个缺点。
Trie树的基本性质可以归纳为:
-
根节点不包含字符,除根节点以外每个节点只包含一个字符。
-
从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
-
每个节点的所有子节点包含的字符串不相同。
(2)Patricia Tries(前缀树)
前缀树跟Trie树的不同之处在于:Trie树给每一个字符串分配一个节点,这样将使那些很长但又没有公共节点的字符串的Trie树退化成数组。前缀树的不同之处在于如果节点具有公共前缀,那么就使用公共前缀,否则就把剩下的所有节点插入同一个节点。Patricia相对Tire的优化如下图:
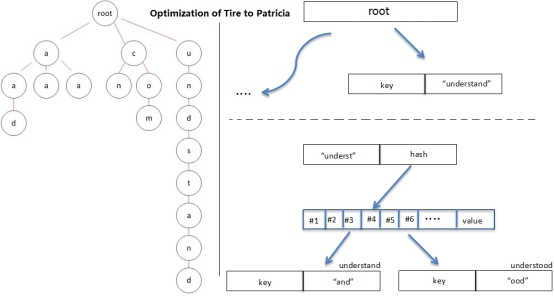
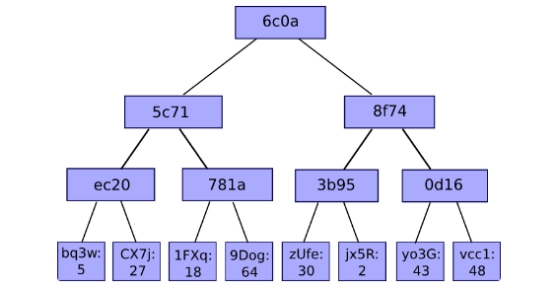
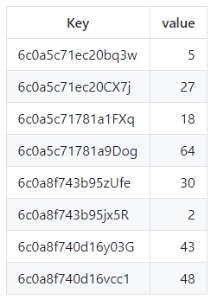
上图存储的8个Key Value对,可以看到前缀树的特点。
(3)Merkle树:
Merkle Tree,通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。Merkle树的叶子是数据块(例如,文件或者文件的集合)的hash值。非叶节点是其对应子节点串联字符串的hash。
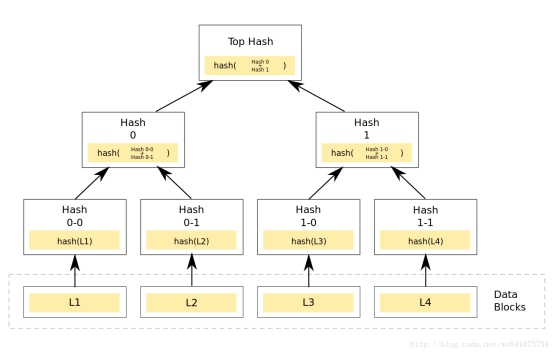
Merkle Tree的主要作用是当拿到Top Hash的时候,这个hash值代表了整颗树的信息摘要,当树里面任何一个数据发生了变动,都会导致Top Hash的值发生变化。 而Top Hash的值是会存储到区块链的区块头里面去的, 区块头是必须经过工作量证明。 这也就是说只要拿到一个区块头,就可以对区块信息进行验证。
(4)MPT存储与查询流程:
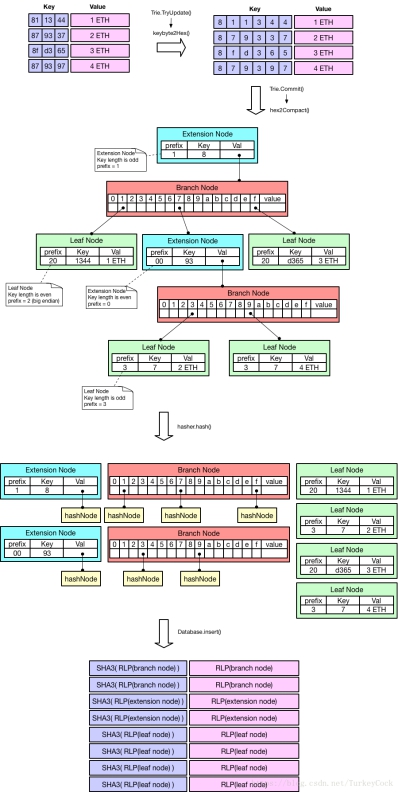
下面是节点的结构:
//trie/node.go
type node interface {
fstring(string) string
cache() (hashNode, bool)
}
type (
fullNode struct { //branchNode
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct { //extension node or leaf node
Key []byte
Val node
flags nodeFlag //prefix
}
hashNode []byte //
valueNode []byte //
)
由于是采用nibble作为路径单位,所以先将路径和值都写为字节形式:

那么在数据库中存储形式为:
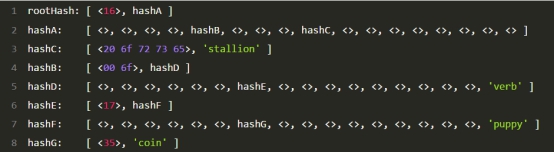
查询值为coin的流程如下:
(1)rootHash已知(存储在区块头中),那么从levelDB中读出key为rootHash的值,也就是[ <16>, hashA ],这是一个扩展节点,路径为6,剩下路径为4,6,f,6,7,6,5,并得到下一个节点hashA
(2)在levelDB中读出key为hashA的值,也就是 [ <>, <>, <>, <>, hashB, <>, <>, <>, hashC, <>, <>, <>, <>, <>, <>, <>, <> ],nibble为4,在位置4读出下一个节点hashB,剩余路径为6,f,6,7,6,5
(3)在levelDb中读出key为hashB的值,也就是[ <00 6f>, hashD ],这是一个路径为6f的扩展节点,因此剩余路径为6,7,6,5,并得到下一个节点hashD
(4)在levelDb中读出key为hashD的值,也就是 [ <>, <>, <>, <>, <>, <>, hashE, <>, <>, <>, <>, <>, <>, <>, <>, <>, ‘verb’ ],nibble为6,在位置6读出下一个节点hashE,剩余路径为7,6,5
(5)在levelDb中读出key为hashE的值,也就是 [ <17>, hashF ],这是一个路径为7的扩展节点,因此剩余路径为65,并得到下一个节点hashF
(6)在levelDb中读出key为hashF的值,也就是[ <>, <>, <>, <>, <>, <>, hashG, <>, <>, <>, <>, <>, <>, <>, <>, <>, ‘puppy’ ],nibble为6,在位置6读出下一个节点hashG,剩余路径为5
(7)在levelDb中读出key为hashG的值,也就是[ <35>, ‘coin’ ],这是一个路径为5的叶节点,正好和我们的剩余路径吻合,因此我们就得到了最终的值coin。
3、Transactions与Receipts的存储
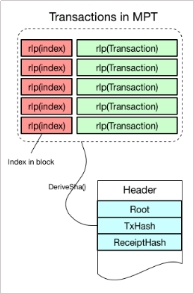
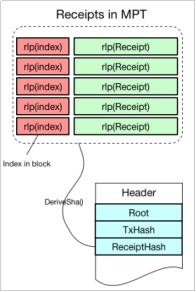
从图中可以看出,MPT中是以交易在区块中的索引的RLP编码作为key,存储交易数据的RLP编码。
其中DeriveSha() 操作代码如下:
type DerivableList interface {
Len() int
GetRlp(i int) []byte
}
func DeriveSha(list DerivableList) common.Hash {
keybuf := new(bytes.Buffer)
trie := new(trie.Trie)
for i := 0; i < list.Len(); i++ {
keybuf.Reset()
rlp.Encode(keybuf, uint(i))
trie.Update(keybuf.Bytes(), list.GetRlp(i))
}
return trie.Hash()
}
其中的trie.Update实现如下:
//trie/trie.go
func (t *Trie) Update(key, value []byte) {
if err := t.TryUpdate(key, value); err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
}
}
func (t *Trie) TryUpdate(key, value []byte) error {
k := keybytesToHex(key)
if len(value) != 0 {
_, n, err := t.insert(t.root, nil, k, valueNode(value))
if err != nil {
return err
}
t.root = n
} else {
_, n, err := t.delete(t.root, nil, k)
if err != nil {
return err
}
t.root = n
}
return nil
}
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) {
if len(key) == 0 {
if v, ok := n.(valueNode); ok {
return !bytes.Equal(v, value.(valueNode)), value, nil
}
return true, value, nil
}
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
// If the whole key matches, keep this short node as is
// and only update the value.
if matchlen == len(n.Key) {
dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value)
if !dirty || err != nil {
return false, n, err
}
return true, &shortNode{n.Key, nn, t.newFlag()}, nil
}
// Otherwise branch out at the index where they differ.
branch := &fullNode{flags: t.newFlag()}
var err error
_, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val)
if err != nil {
return false, nil, err
}
_, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value)
if err != nil {
return false, nil, err
}
// Replace this shortNode with the branch if it occurs at index 0.
if matchlen == 0 {
return true, branch, nil
}
// Otherwise, replace it with a short node leading up to the branch.
return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
case *fullNode:
dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value)
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
return true, n, nil
case nil:
return true, &shortNode{key, value, t.newFlag()}, nil
case hashNode: // according to hashnode finding node(maybe extension node and branch node )
// We've hit a part of the trie that isn't loaded yet. Load
// the node and insert into it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.insert(rn, prefix, key, value)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v", n, n))
}
}